
Ning Wang
I am a researcher in the BiLiBiLi, Beijing . My research interests are deep learning and computer vision which includes visual tracking, video object segmentation, vitrual Try-On , face detection &and recognization. I did my Bachelors at school of , Nanjing University of Information Science & Technology, where I was advised by Prof. Kaihua Zhang . I was a full-time research intern in the Intelligent Driving Group of Baidu from from December 2020 to June 2021, supervised by Dr. Lei He. I am expected to apply for Ph.D. starting from 2022 Fall. Here is my Curriculum Vitae.
News
Recent Projects

Github Code | Paper | Demo-Video Code
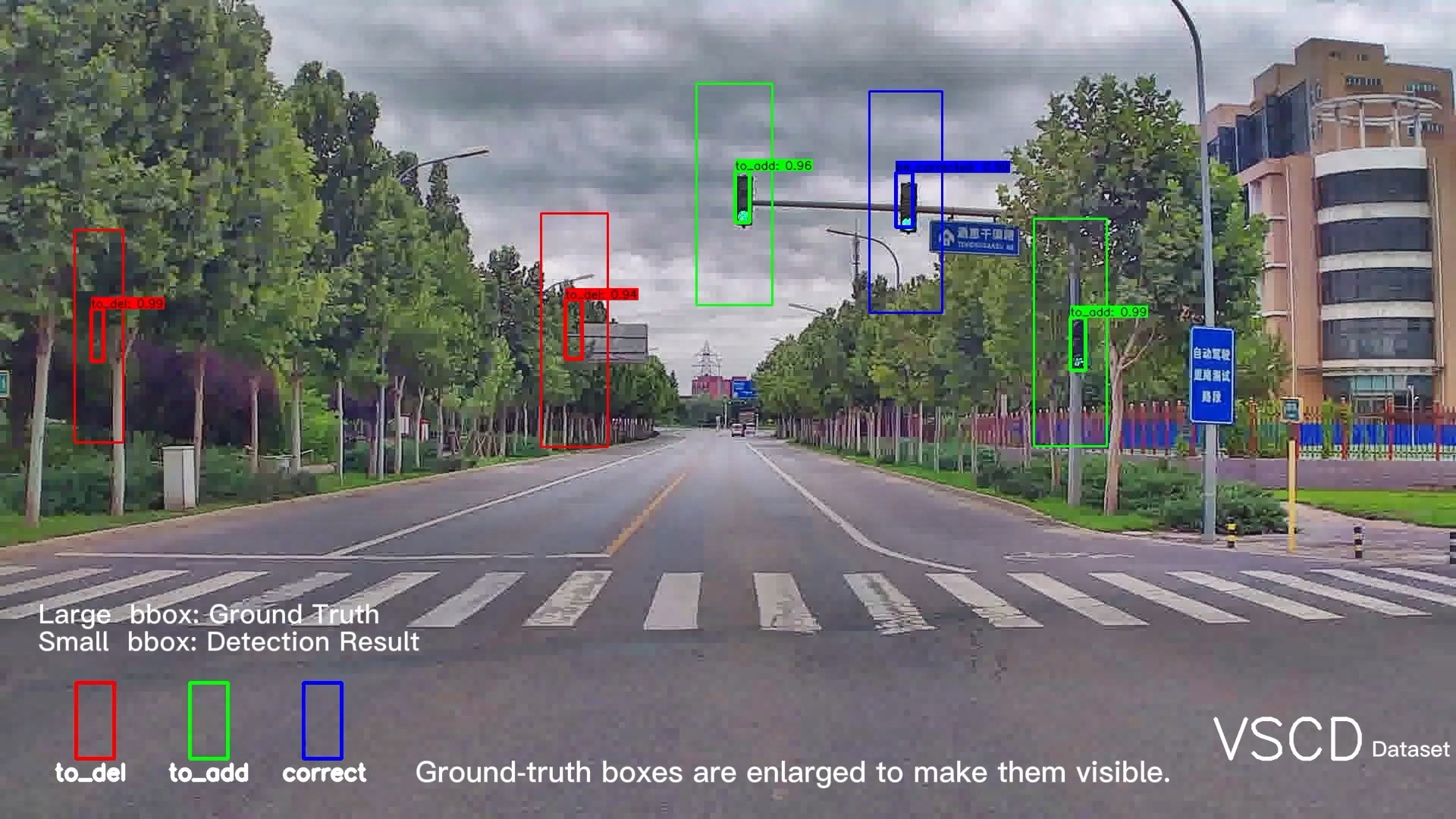
Up-to-date High-Definition (HD) maps are essential for self-driving cars. To achieve constantly updated HD maps, we present a deep neural network (DNN), Diff-Net, to detect changes in them. Compared to traditional methods based on object detectors, the essential design in our work is a parallel feature difference calculation structure that infers map changes by comparing features extracted from the camera and rasterized images. To generate these rasterized images, we project map elements onto images in the camera view, yielding meaningful map representations that can be consumed by a DNN accordingly. As we formulate the change detection task as an object detection problem, we leverage the anchor-based structure that predicts bounding boxes with different change status categories. To the best of our knowledge, the proposed method is the first end-to-end network that tackles the high-definition map change detection task, yielding a single stage solution. Furthermore, rather than relying on single frame input, we introduce a spatio-temporal fusion module that fuses features from history frames into the current, thus improving the overall performance. Finally, we comprehensively validate our method's effectiveness using freshly collected datasets. Results demonstrate that our Diff-Net achieves better performance than the baseline methods and is ready to be integrated into a map production pipeline maintaining an up-to-date HD map. I was responsible for coding, experiments and part of this paper.
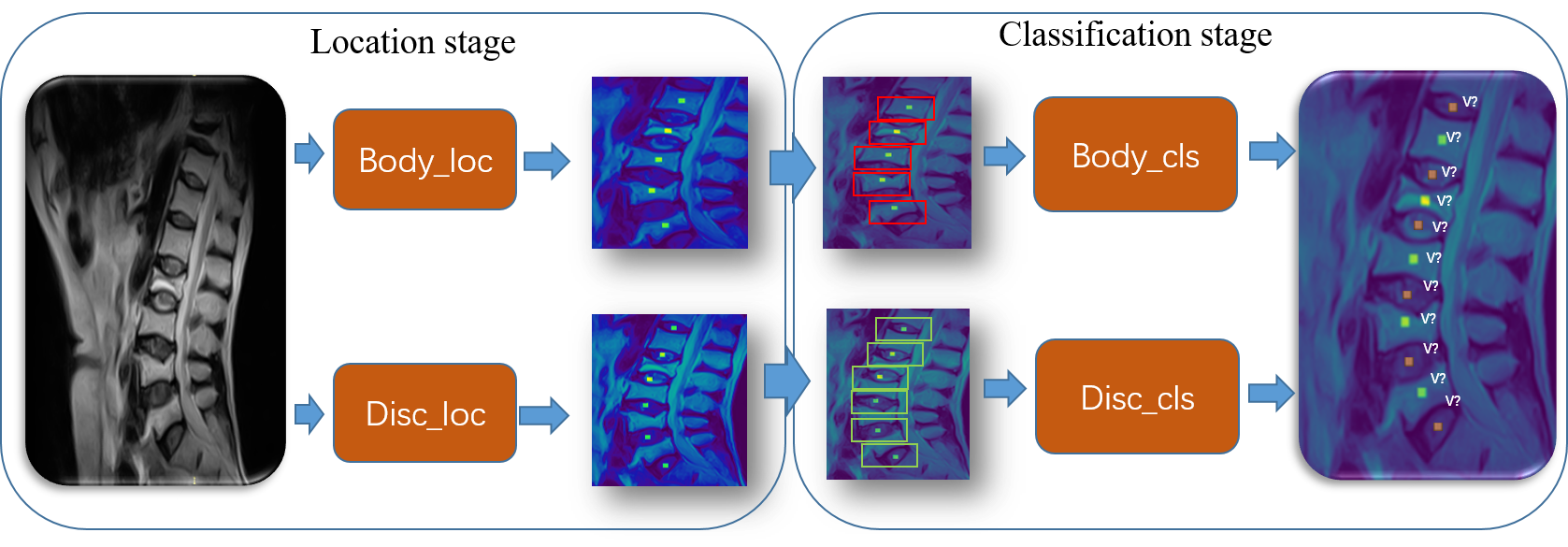
We introduce a general python framework for medical image processing and intelligent medical diagnostic, which is applied in our spine diagnostic task. We share the guide in Readme file and you can transfer to any other project easily. PyDoctor introduce a diagnose architecture consisting of two components designed exclusively for target location and target classification. Target location: We decomposed location-stage with body_loc(vertebral body) and disc_loc(intervertebral disc).Here are our PyDoctor location result on testB.See more images here body_loc & disc_loc Target classification: We also decomposed classification-stage with body_cls and disc_cls. After obtaining the locations of body or disc, we crop patches from images and resize into fixed scale.
We introduce a method specifically designed for UAV infrared video which contains bounch of challenges such as small-similar-objects, fast-camera-motion and lack-of-color . The codes and paper coming soon.

Research
I'm interested in devleoping Interesting models for computer vision (e.g. Virtual Try-ON, Single Object Tracking or Segmentation) using Code.
Conference Papers:
Album
